
第5章:非機能要件の折り込み
要件の種類
以前の投稿で要件定義を行いましたが、実は抽出した項目は機能要件と呼ばれるものです。では機能要件と非機能要件とは何でしょうか。
- 機能要件とは
アプリが何をできるかを示したもの。
最初に実施したように音声でメモできるなど。私たちが実際に使用するために作りこみたいと考えたもののことです。そのため、比較的容易に直感的に記載することができます。
- 非機能要件とは
アプリがどうあるべきかを示したもの。
アプリの品質や使いやすさ、安全性を示す要件のため、直感的には出てこないことが多いです。
少しイメージしにくいかと思います。今回は非機能要件とは何なのかをもう少し詳しく説明します。
非機能要件とは
非機能要件とは品質や使いやすさを指示するため、非機能要件を逃していると後になってこれ不便だなと感じたり、場合によっては致命的な不具合を生みます。
今回の例ではマイクは選択可能であること。という要件が実現できていないため、音声が入力できないという致命的な課題にぶつかりました。
非機能要求について詳しく知りたい方はまたまたIPAのこちらを参照ください。
非機能要件の検討
本ブログは業務で大規模システムを作ることも目的とはしていないため、大規模な分析活動は行わずず、アプリ動作確認や要件定義時に思いついたものから入れていくことにしましょう。
実際の機能要件には分析の足掛かりとなる、カテゴリー分けがあります。性能、可用性、信頼性、保守性etc,,
ですが、ここではまず3つキーワードだけ覚えましょう。
- 性能
応答時間、処理速度、同時接続数、メモリ使用量など
例えば、すべての音声を録音してから文字に起こすのではなく、音声入力したらすぐに文字起こししてほしい。 - ユーザビリティ
直感的で使いやすいUI/UXなど
例えば、音声を入力するためのマイクは選択可能にすること。 - 技術的制約(設計制約)
言語の指定やライブラリの制約等はここに記載する。
無料のライブラリのみを使用してほしいなんて記載でもOK。
第6章:要件修正と動作確認
要件定義
非機能要件を含めて以下のような要件定義を行いました。
音声認識メモアプリ
機能要件(= アプリが何をできるべきか)
ユーザーのニーズを実現する「機能」に関する要件です。
・音声認識機能
音声をもとにメモを作成する。
・プレビュー画面
作成されたメモを画面上で確認できるようにする。
・録音の開始ボタン
任意のタイミングで録音を開始できるようにする。
・音声入力までの待機
録音中、無音の間は動作を待機させる。
・文字起こし(リアルタイム)
音声入力後、即時に文字起こしを行う。
・録音の終了ボタン
ユーザー操作で録音を明示的に停止できる。
・データの保存
文字起こし結果をテキストファイルとして保存する機能。
非機能要件(= どう実現するかの制約や品質)
・ユーザビリティ
マイクをユーザーが選択できるようにする(操作性の向上)。
直感的なUI設計(例:ボタン表示やメッセージの明確さ)も含めてよい。
音声がない時に認識できないことをメモ範囲外に記載する。
ウィンドウ縮小時にも、操作ボタン・ステータス表示が常に表示されるようにする(スクロールや圧縮によって消えないこと)。
・性能
リアルタイムで文字起こしできる程度の処理速度を持つ。
録音と変換に待ち時間が少ないこと。
・技術的制約(設計制約)
言語はPythonを使用
GUIはTkinterで作成する。※いくつかの要件は一度生成した後に追加したものがあります。
コード生成
生成されたコードがこちら
import tkinter as tk
from tkinter import filedialog, scrolledtext, messagebox, ttk
import threading
import speech_recognition as sr
import os
import datetime
import tempfile
import wave
import pyaudio
import json
CONFIG_FILE = "settings.json"
DEFAULT_SETTINGS = {
"sensitivity": 1.0,
"mic_index": 0
}
def load_settings():
if os.path.exists(CONFIG_FILE):
with open(CONFIG_FILE, "r", encoding="utf-8") as f:
return json.load(f)
return DEFAULT_SETTINGS.copy()
def save_settings(settings):
with open(CONFIG_FILE, "w", encoding="utf-8") as f:
json.dump(settings, f, ensure_ascii=False, indent=2)
def get_valid_microphones():
p = pyaudio.PyAudio()
valid_devices = []
for i in range(p.get_device_count()):
info = p.get_device_info_by_index(i)
if info["maxInputChannels"] > 0:
try:
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
input_device_index=i,
frames_per_buffer=1024)
stream.close()
valid_devices.append(info["name"])
except Exception:
continue
p.terminate()
return valid_devices
SETTINGS = load_settings()
class VoiceMemoApp:
def __init__(self, root):
self.root = root
self.root.title("音声認識メモアプリ")
self.root.geometry("800x600")
self.recognizer = sr.Recognizer()
self.microphones = get_valid_microphones()
self.audio_frames = []
self.recording = False
self.create_widgets()
def create_widgets(self):
self.root.rowconfigure(2, weight=1)
self.root.columnconfigure(0, weight=1)
config_frame = tk.Frame(self.root)
config_frame.grid(row=0, column=0, sticky="ew", padx=10, pady=(10, 0))
tk.Label(config_frame, text="感度:").pack(side=tk.LEFT)
self.sensitivity_scale = tk.Scale(config_frame, from_=0.5, to=3.0, resolution=0.1,
orient=tk.HORIZONTAL, length=100)
self.sensitivity_scale.set(SETTINGS["sensitivity"])
self.sensitivity_scale.pack(side=tk.LEFT)
tk.Button(config_frame, text="⚙ 設定変更", command=self.open_settings_window).pack(side=tk.LEFT, padx=10)
control_frame = tk.Frame(self.root)
control_frame.grid(row=1, column=0, sticky="ew", padx=10, pady=10)
self.record_button = tk.Button(control_frame, text="🔴 録音開始", command=self.toggle_recording)
self.record_button.grid(row=0, column=0, padx=5)
tk.Button(control_frame, text="📂 メモ保存", command=self.save_memo).grid(row=0, column=1, padx=5)
tk.Button(control_frame, text="📂 ログを読み込み", command=self.load_log).grid(row=0, column=2, padx=5)
self.text_area = scrolledtext.ScrolledText(self.root, font=("Meiryo", 12))
self.text_area.grid(row=2, column=0, sticky="nsew", padx=10, pady=10)
self.status_bar = tk.Label(self.root, text="準備完了", bd=1, relief=tk.SUNKEN, anchor=tk.W)
self.status_bar.grid(row=3, column=0, sticky="nsew")
self.root.rowconfigure(3, weight=0)
def update_status(self, msg):
self.status_bar.config(text=msg)
self.status_bar.update_idletasks()
def open_settings_window(self):
settings_window = tk.Toplevel(self.root)
settings_window.title("設定変更")
settings_window.geometry("400x200")
tk.Label(settings_window, text="マイク選択:").pack(pady=5)
mic_combo = ttk.Combobox(settings_window, values=self.microphones, width=45)
mic_combo.pack()
mic_combo.current(min(SETTINGS.get("mic_index", 0), len(self.microphones) - 1))
def apply():
SETTINGS["sensitivity"] = self.sensitivity_scale.get()
SETTINGS["mic_index"] = mic_combo.current()
save_settings(SETTINGS)
self.update_status("設定を保存しました")
settings_window.destroy()
tk.Button(settings_window, text="保存して閉じる", command=apply).pack(pady=10)
def toggle_recording(self):
if self.recording:
self.recording = False
self.record_button.config(text="🔴 録音開始")
self.update_status("録音停止")
else:
self.recording = True
self.record_button.config(text="⏹ 録音停止")
threading.Thread(target=self.record_audio).start()
def record_audio(self):
self.update_status("録音中...( 停止ボタンで終了 )")
index = SETTINGS.get("mic_index", 0)
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
input_device_index=index,
frames_per_buffer=1024)
self.audio_frames = []
while self.recording:
try:
data = stream.read(1024, exception_on_overflow=False)
if len(data) > 100000:
self.update_status("⚠ 異常なデータサイズを検出、録音停止")
break
self.audio_frames.append(data)
except Exception as e:
self.update_status(f"⚠ 録音エラー: {e}")
break
stream.stop_stream()
stream.close()
p.terminate()
self.update_status("録音完了、文字起こし中...")
if not self.audio_frames:
self.update_status("⚠ 録音データが空のため保存をスキップ")
return
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as temp_audio:
joined = b''.join(self.audio_frames)
if len(joined) > 0xFFFFFFFF:
self.update_status("⚠ 録音データが大きすぎます")
return
wf = wave.open(temp_audio.name, 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(16000)
wf.writeframes(joined)
wf.close()
with sr.AudioFile(temp_audio.name) as source:
audio = self.recognizer.record(source)
try:
text = self.recognizer.recognize_google(audio, language='ja-JP')
self.text_area.insert(tk.END, text + "\n")
self.text_area.see(tk.END)
self.update_status("文字起こし完了")
except sr.UnknownValueError:
self.update_status("⚠ 音声が認識できませんでした")
except Exception as e:
self.update_status(f"⚠ エラー: {e}")
finally:
os.remove(temp_audio.name)
def save_memo(self):
content = self.text_area.get("1.0", tk.END)
if not content.strip():
messagebox.showwarning("警告", "メモが空です。")
return
now = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
file_path = filedialog.asksaveasfilename(
defaultextension=".txt",
initialfile=f"memo_{now}.txt",
filetypes=[("Text Files", "*.txt")]
)
if file_path:
with open(file_path, "w", encoding="utf-8") as f:
f.write(content)
self.update_status(f"メモを保存しました:{file_path}")
def load_log(self):
file_path = filedialog.askopenfilename(filetypes=[("Text Files", "*.txt")])
if file_path:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
self.text_area.delete("1.0", tk.END)
self.text_area.insert(tk.END, content)
self.update_status("過去のメモを読み込みました")
if __name__ == "__main__":
root = tk.Tk()
app = VoiceMemoApp(root)
root.mainloop()
動作確認
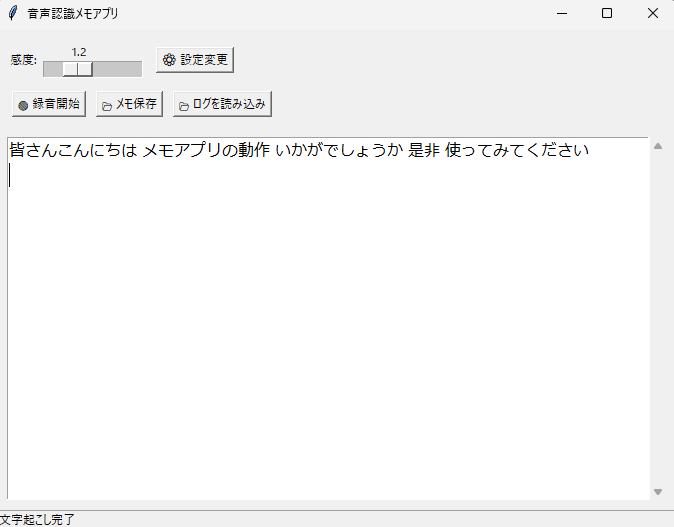
動作に問題はなく、意図通りのアプリが作成できました。
第6章:まとめと振り返り
実施内容
ここまでの記事では以下の検討を通して一つのアプリを作成してみました。
- 機能要件定義
- フローチャート作成
- 非機能要件定義
- アプリ生成
いかがだったでしょうか?コード未経験の方でも可能性があるなと感じてもらえたらうれしいです。
不足点や質問についてもぜひ、教えてもらえたら可能な限り対応させていただきます。
また次回のアプリの案なども以下のフォームから送っていただけると喜びます。

{kind=link}
コメント